Load testing Heroku's 1X, 2X and PX dynos

Heroku has 3 different dyno sizes, 1X, 2X and now the new PX dyno.
The PX is a huge box with 6GB of RAM and 40x the compute power of the standard 1X dyno (whatever that means, Heroku’s docs aren’t super clear about what a compute unit is).
This dyno is monsterous in comparison with Heroku’s 1X (512mb) and 2X (1024mb) dynos. And very large for the typical web application.
I wanted to see what kind of performance gains I could get from running the same Rails app on the different dyno sizes. So I setup a basic Rails app and ran load tests against each different dyno size.
Disclaimer: Any load test is HIGHLY dependant on the specific application that’s running. These results won’t be the same for your app. The app I’m testing here is very simple and used for comparison between dyno sizes.
The Test
I setup a very basic Rails app running on Unicorn. Source is on GitHub. I used Blitz.io to send traffic at it until it started failing and recorded the results. This app doesn’t use any form of caching. With memcache added all of these test results could be significantly better.
Unicorn
I adjusted Unicorn concurrency based on the size of the Dyno. The more unicorn workers running = the more concurrent web requests a dyno can serve. Each unicorn worker takes up X mb in RAM. Best practice is to run your dynos at 50-70% memory usage. For the 1x and 2x dynos I adjust according to that scale. Since this app is really basic, the number of unicorn workers I was able to run was very high.
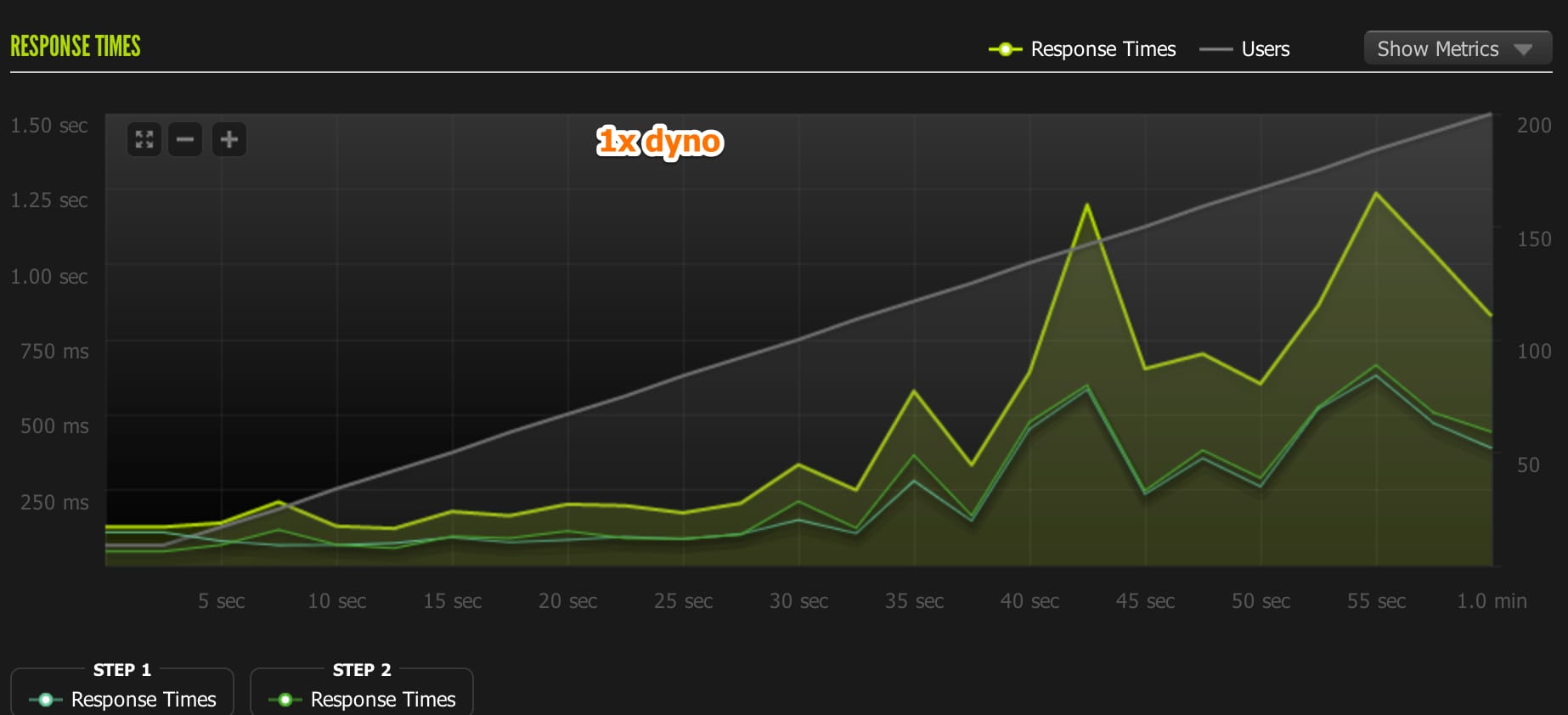
1X Dyno - The Baseline
1st test: (passed) 1-200 concurrent users Unicorn Workers: 8 Requests/sec: 37.81 Avg response time: 463 ms. Load average: 4 Memory Usage: 350mb.
2nd test: (failed) 1-250 concurrent users Unicorn Workers: 8 Requests/sec: 23.81 Avg response time: 543 ms. Load average: Peaked at 7 Memory Usage: 350mb
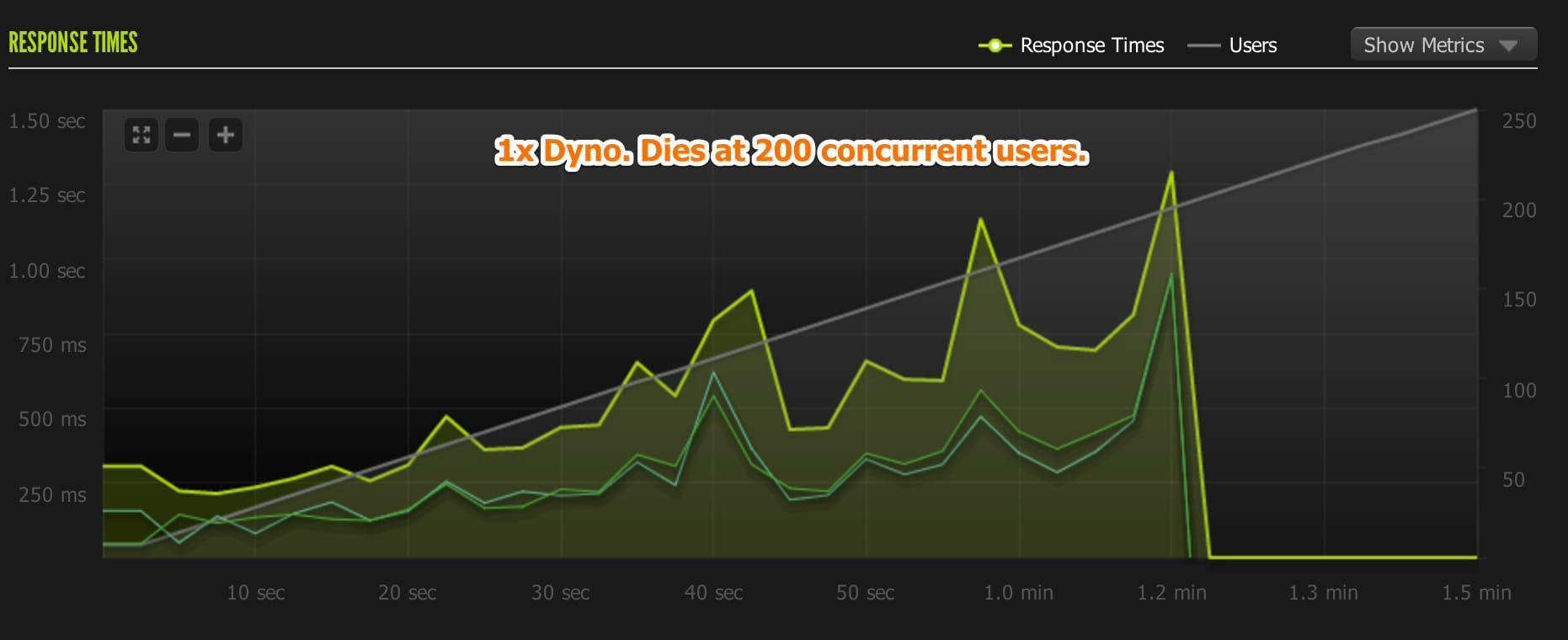
1X Dyno Learnings
This test was to set a baseline for comparing the other dyno sizes. The 1X dyno was CPU constrained due to the high number of Unicorn workers I was running.
Each dyno has access to 4 virtual cores. So a load of 4 means the CPU is fully utilized. For the 1X dyno, requests begain timing out once the load went above 4.
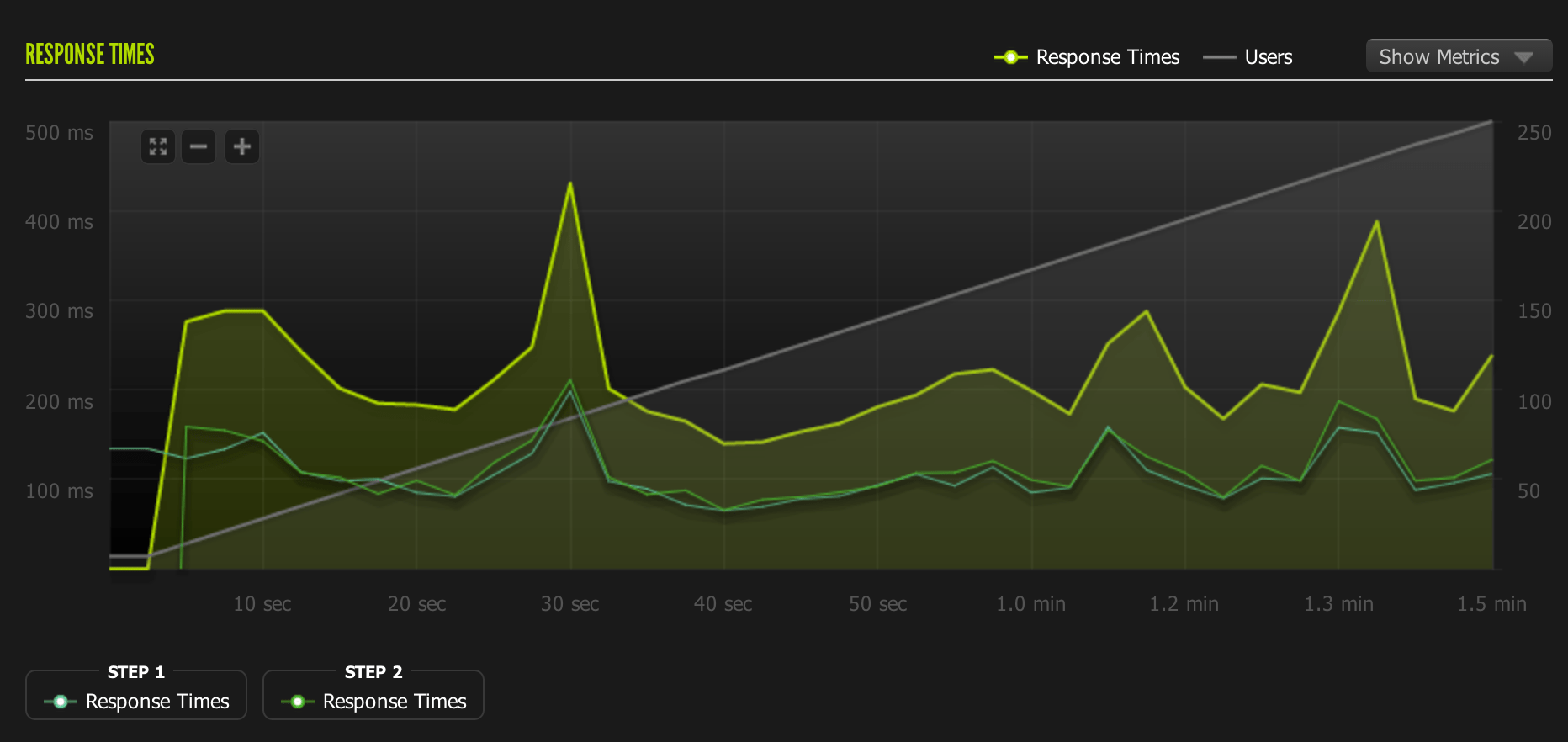
2X Dyno
1st test: (passed) 1-250 concurrent users Unicorn Workers: 14 Requests/sec: 55 Avg response time: 218 ms. Load average: Peaked at 8 Memory Usage: 600mb.
2nd test: (failed) 1-350 concurrent users Unicorn Workers: 18 Requests/sec: 30 Avg response time: 506 ms. Load average: Peaked at 10 Memory Usage: 720mb
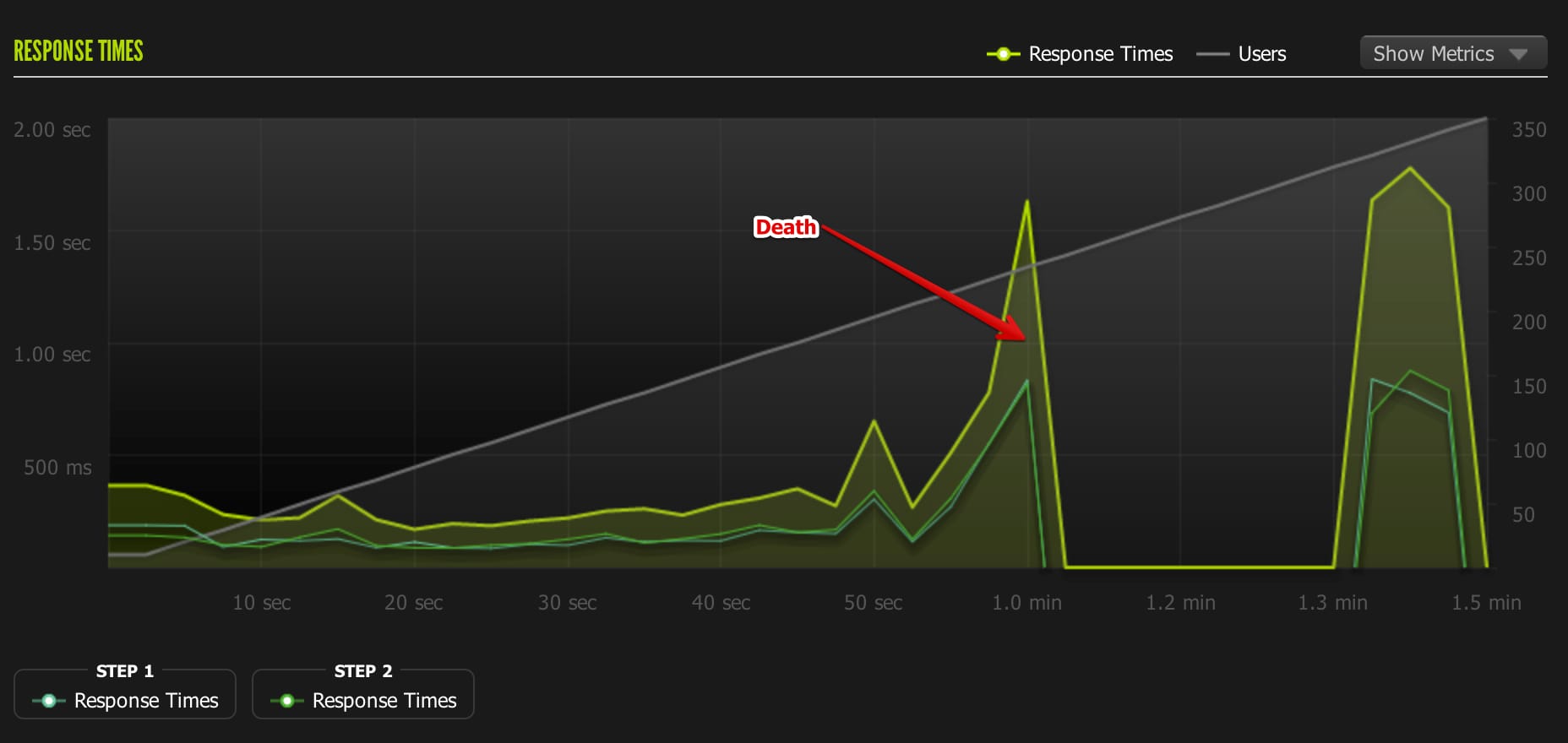
2X Dyno Learnings
I was most impressed with the difference between the 1x and 2x dyno. There’s a very sizable difference in performance between the two. The 1X dyno started to time out at a max of 200 concurrent users. The 2x dyno easily handled 250 users with a response time around twice as fast as the 1x dyno.
I think this application I’m testing is more likely to be CPU constrained than memory constrained due to its small footprint. I’m attributing the increase in performance mostly to the additional compute power on the 2x dyno.
PX Dyno (vroom vroom!)
1st test: (passed) 1-350 concurrent users Unicorn Workers: 18 Requests/sec: 80 Avg response time: 162 ms. Load average: Peakeed at 1.3 Memory Usage: 700mb.
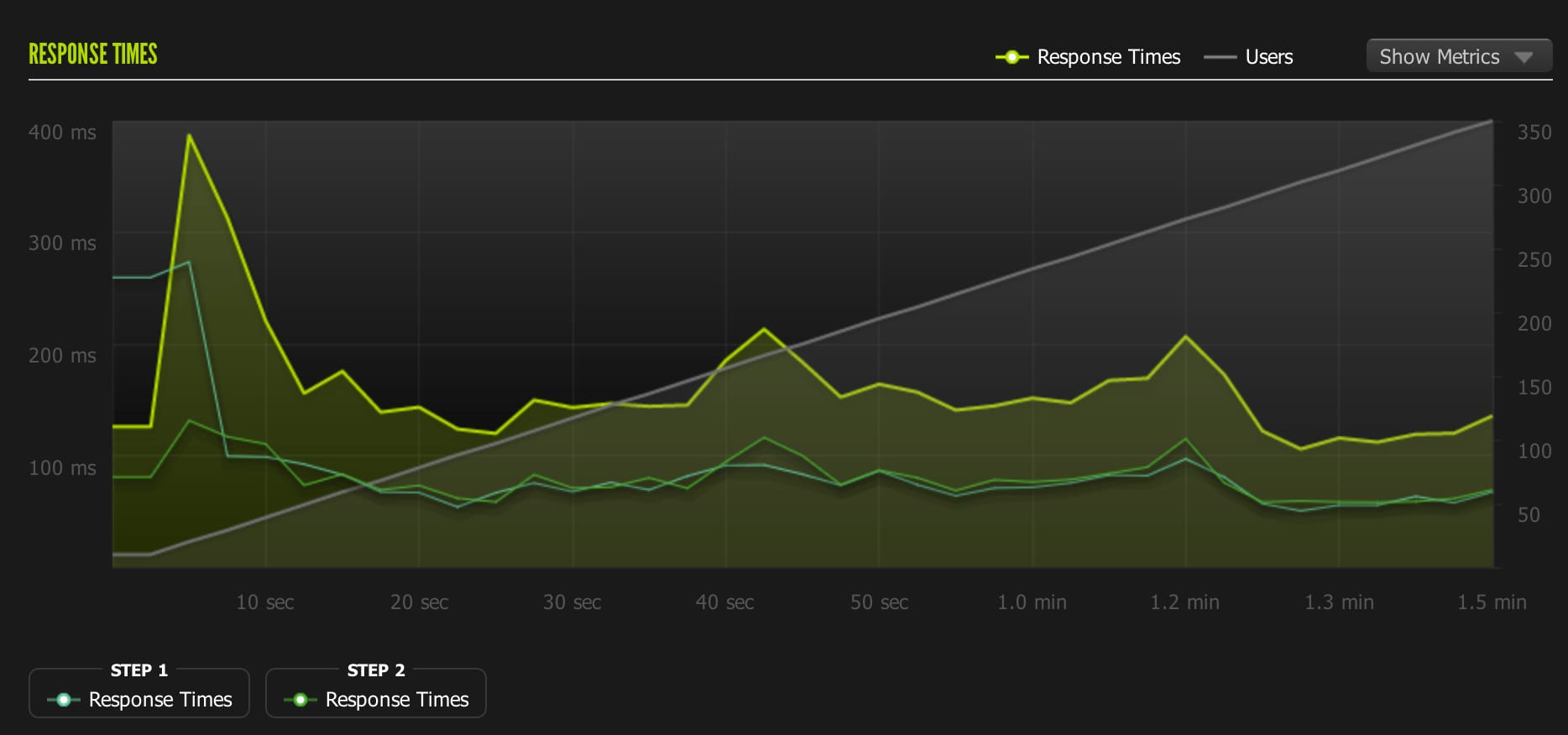
2nd test: (passed) 1-450 concurrent users Unicorn Workers: 18 Requests/sec: 101 Avg response time: 173 ms. Load average: Peaked at 1.23 Memory Usage: 720mb
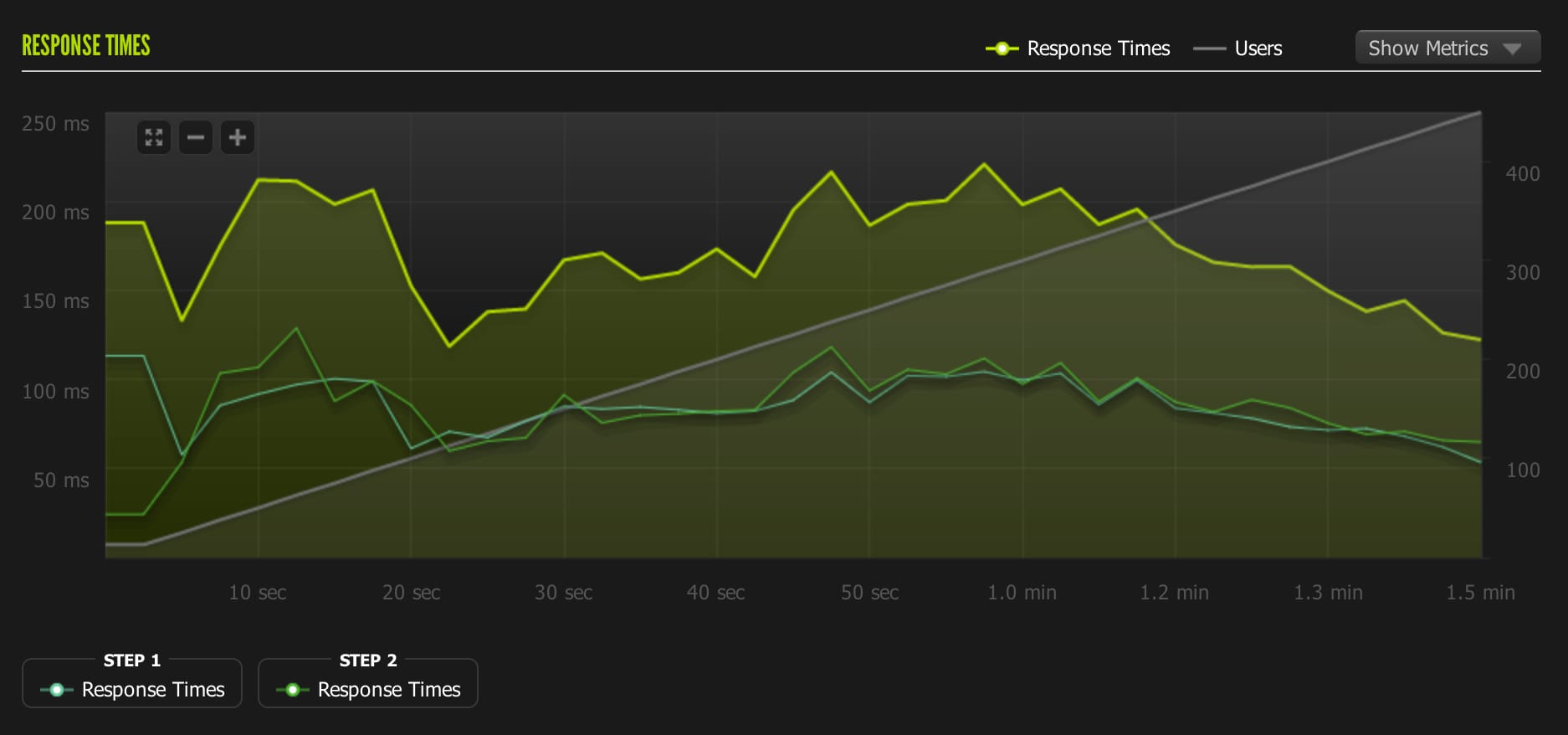
3rd test: (passed) 100-1000 concurrent users Unicorn Workers: 18 Requests/sec: 231 Avg response time: 268 ms. Load average: Peaked at 3.17 Memory Usage: 760mb
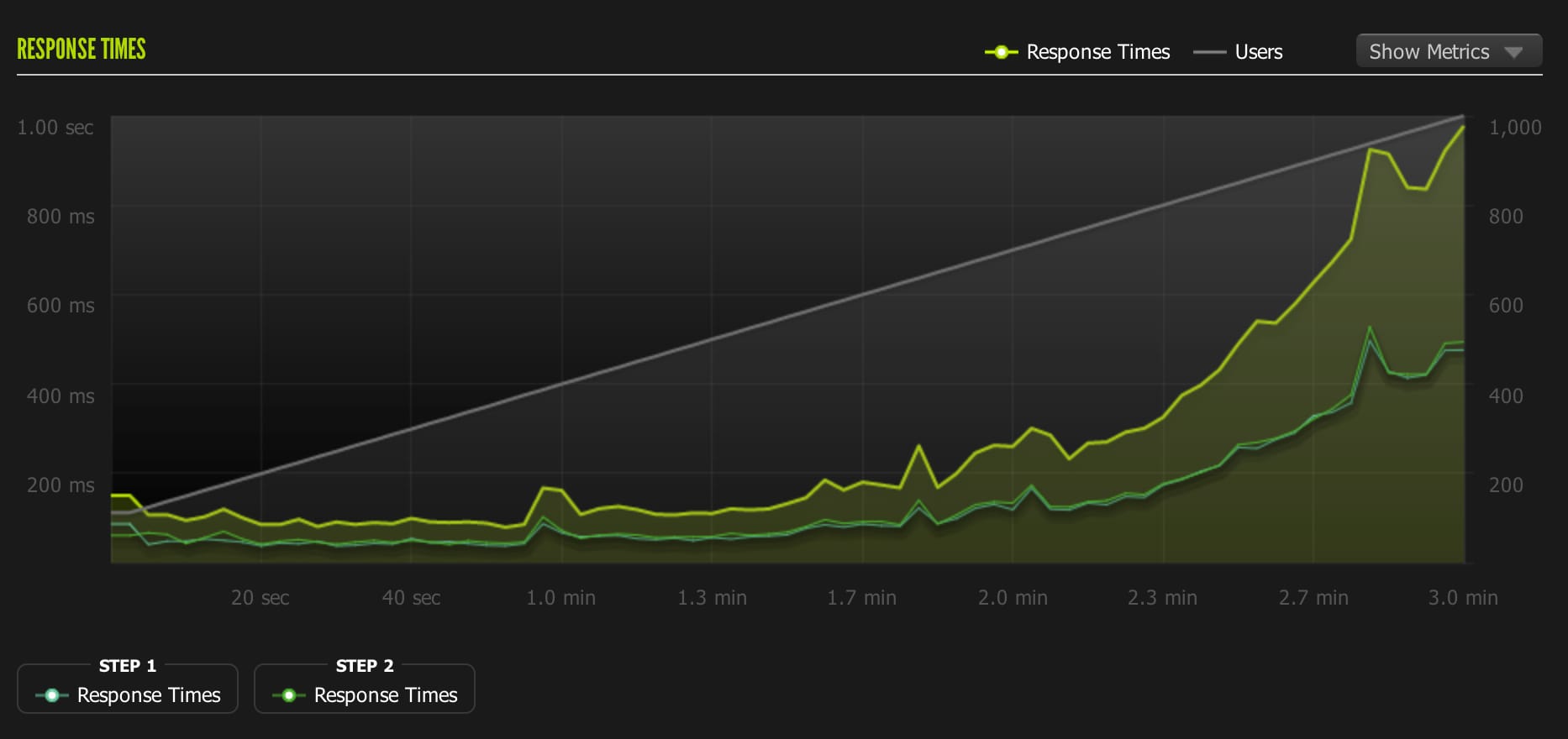
Conclusion
The PX dyno is gigantic for a web app. I barely used the memory available on it and the load stayed low even on the 1,000 user test. I probably should have done another test with a much larger # of unicorn workers running. I think we’d see lower response times and could push it much further. But after the 1,000 user test, I had run out of Blitz credits and didn’t want to spend more money on this little experiment.
Unless you’re running a very large app, the PX dyno overkill and probably best left as a last resort. You should be horizonatally scaling 2X dynos before making the jump to the PX dyno.
Learn more…
- Heroku’s docs are pretty great on explaining dyno sizes.
- Checkout Blitz for load testing.
- For more info on how to performance tune Unicorn. This Digital Ocean blog post is great.